创建工作负载时使用算力资源
更新时间:2026-01-14 06:02:58
配置算力节点后,在创建工作负载时,支持设置算力资源的类型和上限,还可以在容器组的注解中配置算力资源的调度策略。
操作步骤
-
以具有应用负载管理权限的用户登录 KubeSphere Web 控制台并进入您的集群或企业空间。
-
在左侧导航栏选择工作负载。
-
点击部署、有状态副本集或守护进程集打开工作负载列表。
-
在页面点击创建。
-
在基本信息页签,设置工作负载的基本信息,然后点击下一步。
-
在容器组设置页签,为工作负载管理的容器组设置 GPU/NPU 类型、GPU/NPU 使用数量上限。
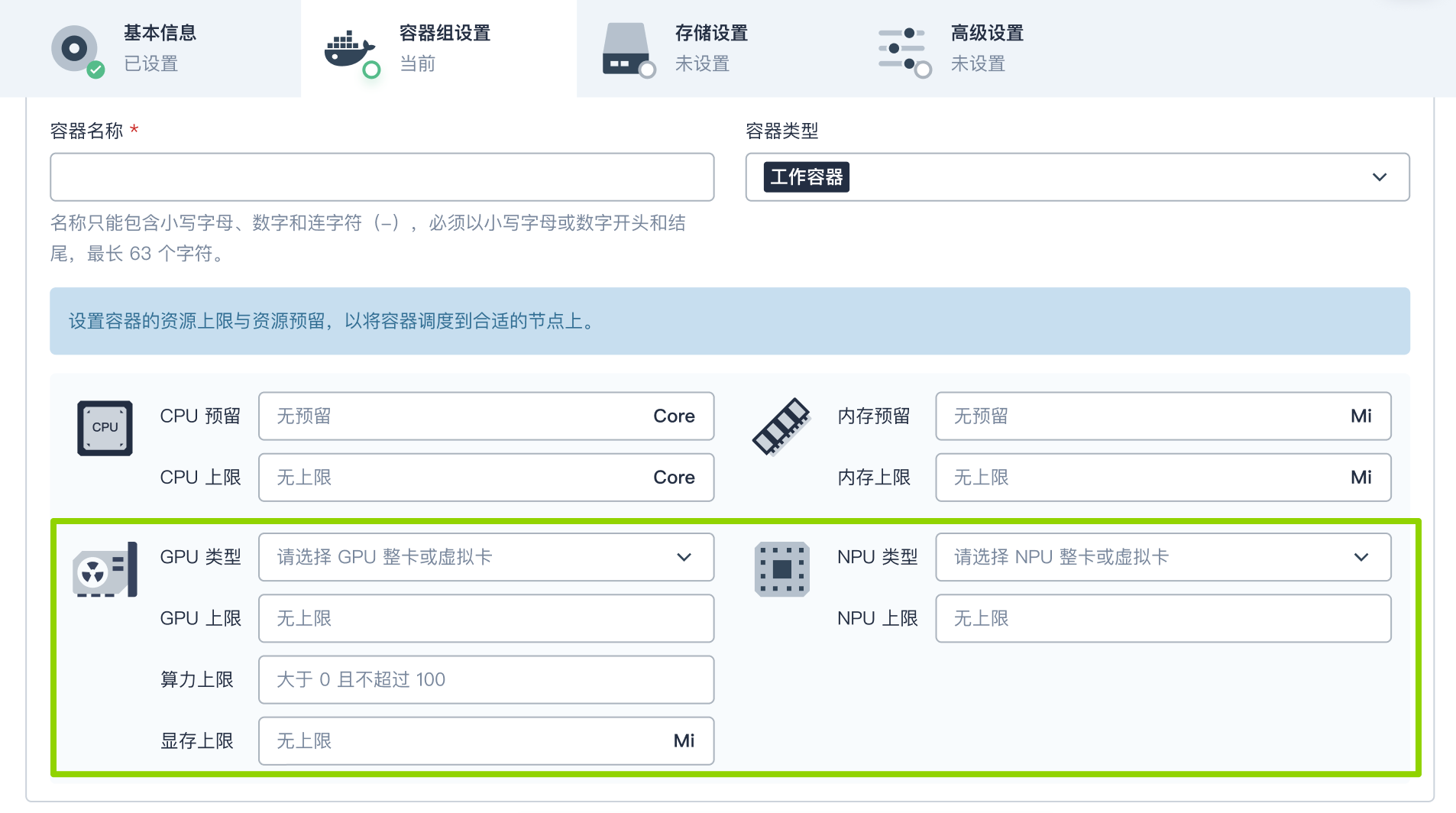
说明 当 “GPU 类型”设置为 GPU 虚拟卡时,方可配置算力和显存上限。
-
在容器组设置页签,还可以添加注解以配置 GPU/NPU 资源的调度策略。
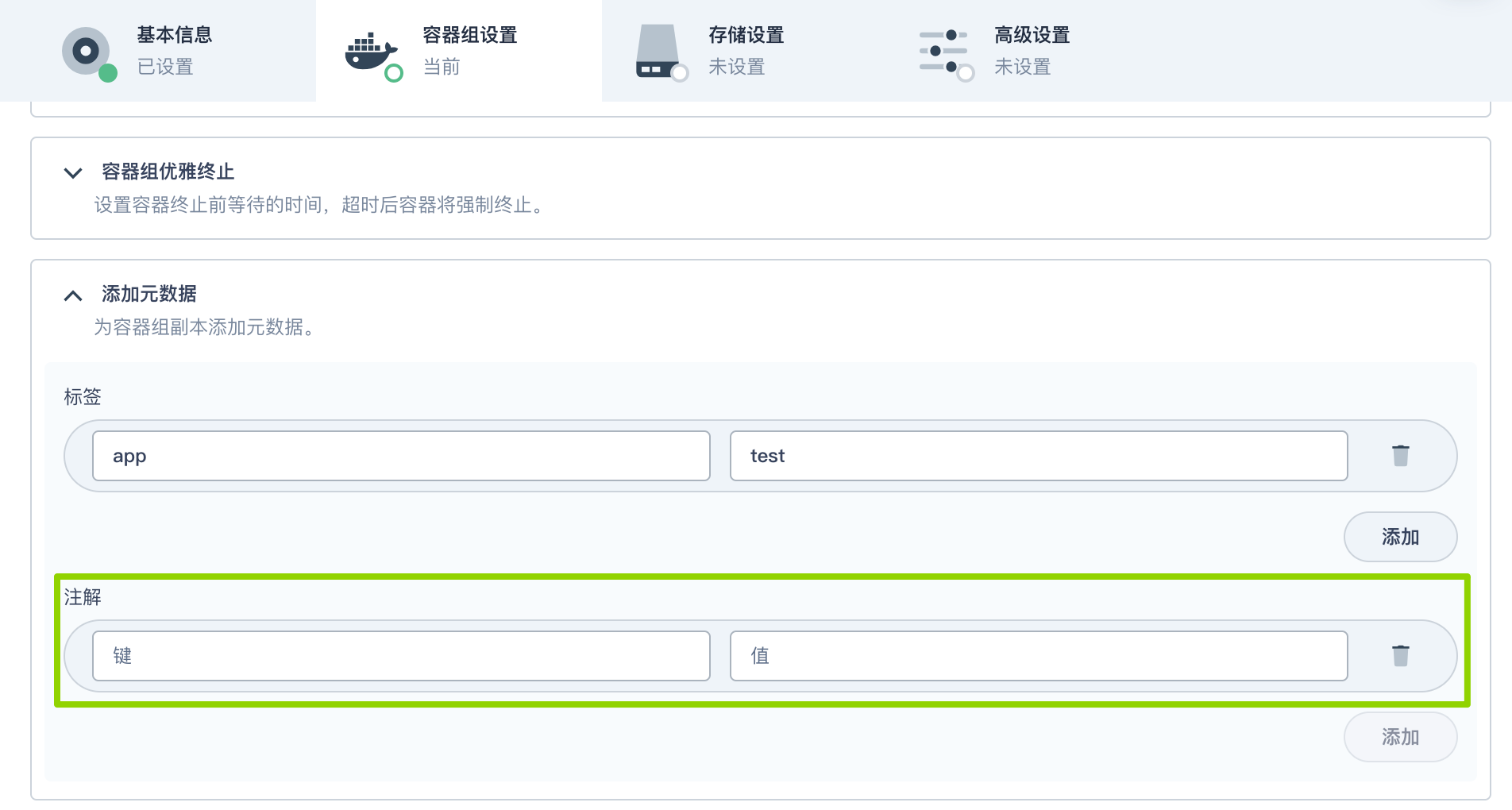
注解示例:
键 值 说明 hami.io/node-scheduler-policy或hami.io/gpu-scheduler-policybinpack 或 spread
-
binpack: 优先填满单卡/单节点,多个 Pod 会优先使用同一个节点。适用于提高利用率的场景。 -
spread: 多个 Pod 会分散在不同节点、不同显卡上,优先选择资源剩余量较多的节点。适用于高可用场景。
nvidia.com/use-gputypeA100,V100
指定 GPU 卡的类型,使用逗号分隔,不会在未指定的卡上启动作业
nvidia.com/nouse-gputype1080,2080
指定黑名单中 GPU 卡的类型,使用逗号分隔,不会在指定的卡上启动作业
nvidia.com/use-gpuuuidGPU-123456
任务将被分配到 UUID 为 GPU-123456 的设备上
说明 更多信息,可参阅 HAMi 官方文档。
-
有关创建工作负载的更多信息,请参阅创建工作负载。