重调度
集群中的调度是将 pending 状态的 Pod 分配到节点运行的过程,在集群之中,Pod 的调度依赖于集群中的调度器(kube-scheduler 或者 Volcano 调度器)。调度器是通过一系列算法计算出 Pod 运行的最佳节点,但是 Kubernetes 集群环境是存在动态变化的,例如某一个节点需要维护,这个节点上的所有 Pod 会被驱逐到其他节点,但是当维护完成后,之前被驱逐的 Pod 并不会自动回到该节点上来,因为 Pod 一旦被绑定了节点是不会触发重新调度的。由于这些变化,集群在一段时间之后就可能会出现不均衡的状态。
为了解决上述问题,Volcano 调度器可以根据设置的策略,驱逐不符合配置策略的 Pod,让其重新进行调度,达到均衡集群负载、减少资源碎片化的目的。
负载感知重调度(LoadAware)
在 K8s 集群治理过程中,常常会因 CPU、内存等高使用率状况而形成热点,既影响了当前节点上 Pod 的稳定运行,也会导致节点发生故障的几率的激增。为了应对集群节负载不均衡等问题,动态平衡各个节点之间的资源使用率,需要基于节点的相关监控指标,构建集群资源视图,在集群治理阶段,通过实时监控,在观测到节点资源率较高、节点故障、Pod 数量较多等情况时,可以自动干预,迁移资源使用率高的节点上的一些 Pod 到利用率低的节点上。
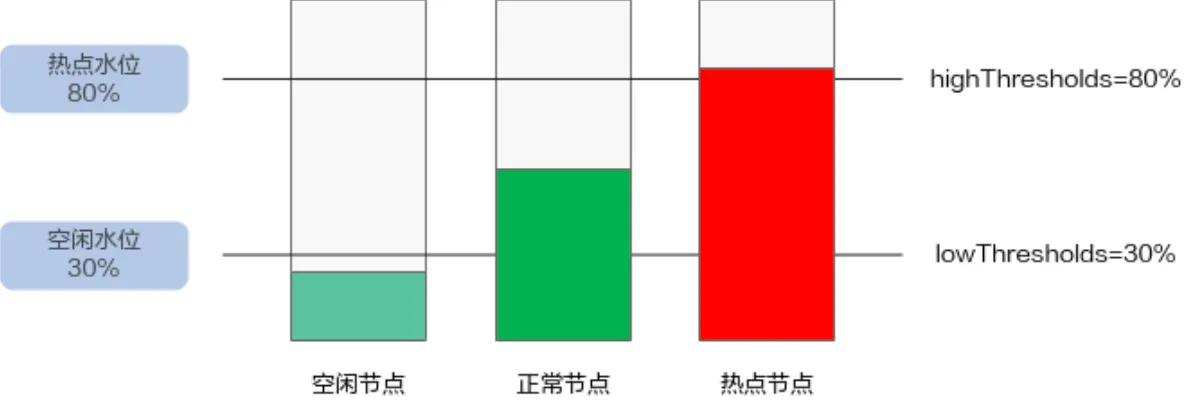
使用该插件时,highThresholds 需要大于 lowThresholds,否则重调度器无法启用。
-
正常节点:资源利用率大于等于 30%且小于等于 80%的节点。此节点的负载水位区间是期望达到的合理区间范围。
-
热点节点:资源利用率高于 80%的节点。热点节点将驱逐一部分 Pod,降低负载水位,使其不超过 80%。重调度器会将热点节点上面的 Pod 调度到空闲节点上面。
-
空闲节点:资源利用率低于 30%的节点。
CPU 和内存资源碎片率整理策略(HighNodeUtilization)
从分配率低的节点上驱逐 Pod。这个策略必须与 Volcano 调度器的 binpack 策略或者 kube-scheduler 调度器的 MostAllocated 策略一起使用。阈值可以分为 CPU 和内存两种资源角度进行配置。
约束与限制
-
重调度之后的 Pod,需要调度器进行调度,重调度器并未进行任何对于 Pod 和节点的标记行为,所以被驱逐的 Pod 调度到节点的行为完全被调度器控制,存在驱逐之后,被驱逐的 Pod 调度到原来节点的可能性。
-
重调度功能暂不支持 Pod 间存在反亲和性的场景。如果使用重调度功能驱逐某个 Pod 后,由于该 Pod 与其他已运行的 Pod 存在反亲和性,调度器仍可能将其调度回驱逐前的节点上。
-
配置负载感知重调度(LoadAware)时,Volcano 调度器需要同时开启负载感知调度;配置 CPU 和内存资源碎片率整理策略(HighNodeUtilization)时,Volcano 调度器需要同时开启 binpack 调度策略。
配置资源碎片整理策略
编辑插件的配置:
volcano-apiserver:
descheduler:
enable: true
image:
registry: docker.io
repository: volcanosh/volcano-descheduler
pullPolicy: IfNotPresent
tag: latest
# Please note that the priority of --descheduling-interval is higher than that of --descheduling-interval-cron-expression. When both parameters are set, the descheduler will follow the behavior defined by --descheduling-interval.
deschedulingIntervalCronExpression: "*/10 * * * *"
# deschedulingInterval: 10m
# refer to https://volcano.sh/zh/docs/descheduler/
policy: |
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- args:
ignorePvcPods: true
nodeFit: true
priorityThreshold:
value: 100
name: DefaultEvictor
- args:
evictableNamespaces:
exclude:
- kube-system
metrics:
address: http://prometheus-k8s.kubesphere-monitoring-system.svc:9090
type: prometheus
thresholds:
cpu: 30
memory: 30
name: HighNodeUtilization
plugins:
balance:
enabled:
- HighNodeUtilization| 参数 | 说明 |
|---|---|
profiles.[].plugins.balance.enable.[] |
指定集群重调度策略类型。 HighNodeUtilization:表示使用资源碎片整理策略。 |
profiles.[].pluginConfig.[].name |
使用负载感知重调度策略时,会使用以下配置:
|
profiles.[].pluginConfig.[].args |
集群重调度策略的具体配置。
|
资源碎片整理策略使用案例
-
在控制台的节点管理页面查看节点的资源使用率,发现存在部分使用率过低的节点。
-
编辑 volcano 插件的参数,这是 CPU 和内存的阈值为 25。表示节点的分配率小于 25%时,该节点上的 Pod 会被驱逐。